









Table of Contents
In mid-June, Meta introduced “Voicebox” with a post on their Meta blog, Meta Newsroom. The blog post “Introducing Voicebox: The Most Versatile AI for Speech Generation” gave key takeaways, such as, “Voicebox is a generative AI model that can help with audio editing, sampling, and styling.” Want to learn more about Meta’s project? Keep reading!
Here’s some more Meta news for you! Read about Meta’s Project P92!
What Makes Meta’s Voicebox Different?
Most other voice-generation AI tools are just that: voice generation. Meta’s Voicebox is different in that Voicebox can not only generate multiple synthetic voices from text but it can also edit pre-recorded audio clips. It can modify any part of an audio clip, not just the end of one.
Meta’s Voicebox can recreate a portion of speech interrupted by noise or replace misspoken words without re-recording the clip. In addition, the model is multilingual, producing audio in six languages (English, French, German, Spanish, Polish, and Portuguese).
Voicebox’s versatility allows for there to be so many different uses for it:
- Increase accessibility for text-based platforms for blind users to hear their articles read to them – and possibly in their native language!
- Make more English platforms accessible to those who do not know English by having them read in their native language.
- Making editing audio for videos easier for content creators and making their videos more accessible to viewers by making them in more languages.
Are you on Threads yet? Read all about Instagram’s new Twitter competitor, Threads!
How Well Does Meta’s Voicebox Work?
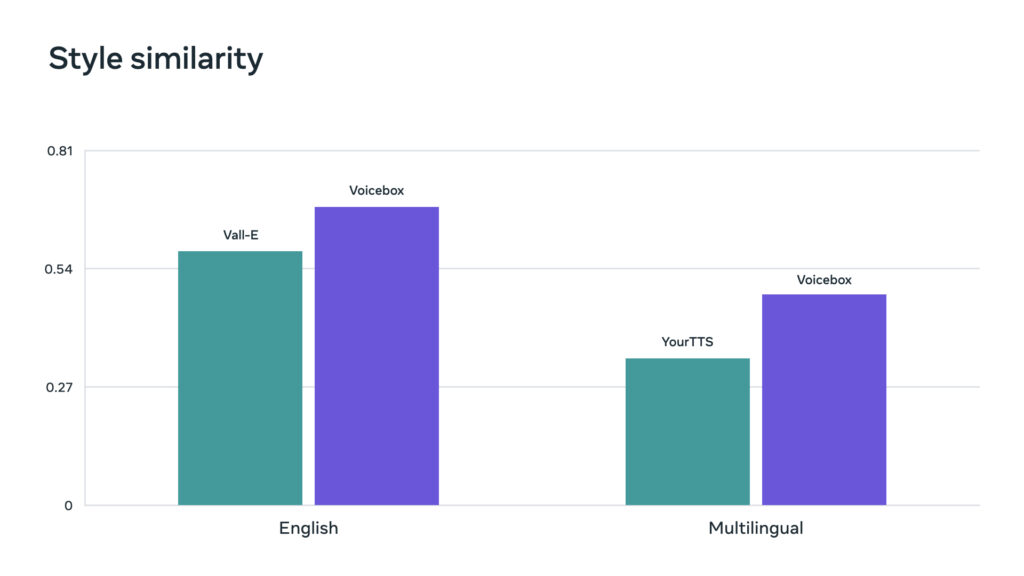
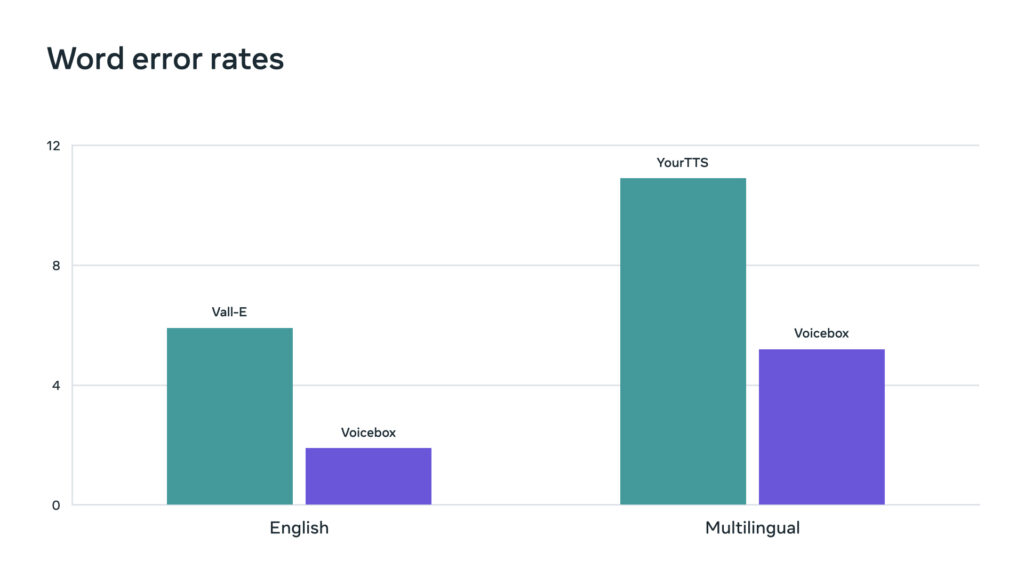
Voicebox currently outperforms Microsoft’s state-of-the-art English model VALL-E regarding both intelligibility and audio similarity while being as much as 20 times faster at audio generation. Regarding multilingual voice synthesis, regarding cross-lingual style transfer, Voicebox outperforms GitHub’s YourTTS, reducing the average word error rate from 10.9 percent to 5.2 percent and improving audio similarity from 0.335 to 0.481.
These influencers will be talking about this! Here are the Top AI Influencers!
How Does Meta’s Voicebox Work?
Voicebox was built upon Meta’s latest advancement on non-autoregressive generative models, the Flow Matching model. This model allows Voicebox to learn highly non-deterministic mapping between text and speech. Non-deterministic mapping is useful because it allows Voicebox to learn from varied speech data without labeling them. This enabled Voicebox to train on a much larger and more diverse scale.
Meta’s Voicebox was trained with more than 50,000 hours of recorded speech and transcripts from public-domain audiobooks in English, French, Spanish, German, Polish, and Portuguese. Voicebox has been trained to predict a segment when given the surrounding speech and the transcript of the segment, having learned to infill speech from context.
Having learned from a diverse set of audio data, Voicebox can generate speech more representative of how people speak in the six languages it recognizes. Meta’s results show that speech recognition models trained on Voicebox-generated speech perform almost as well as models trained on real speech.
The Future of Audio AI
Meta believes Voicebox could “usher in a new era of generative AI for speech.” However, all innovations in AI come with the potential for misuse and harm. Meta anticipated this and programmed Voicebox with a solution: a highly effective classifier that can distinguish between authentic speech and generative AI speech.
Though Meta’s Newsroom blog post does not display an example of Voicebox putting this classifier to use, Meta was empathetic and savvy, having programmed the classifier into it without the issue arising first.
Closing Thoughts
Meta’s Voicebox is a huge innovation in the world of audio-generated AI. With this being the first speech AI to be able to edit audio completely uninhibited, the sky truly seems to be the limit in terms of what and where audio-generated AI can do and go. It is also incredibly comforting to know that Meta has taken the time, energy, and resources to ensure that their AI tool is less likely, if not completely impossible, to be misused or to cause harm. The future of audio-generated AI is out there and ready to be explored!